Dear friend today we will see What is ReplicaSet and how to create ReplicaSet in Kubernetes? so let’s start and see step by step this process.
In the world of cloud-native computing and container orchestration, Kubernetes has become the go-to platform for deploying and managing applications at scale. One of the core building blocks of Kubernetes is the ReplicaSet—a concept that ensures high availability, fault tolerance, and scalability of applications. In this blog post, we’ll dive deep into what a ReplicaSet is, how it works, and how you can create and manage ReplicaSets effectively in your Kubernetes environment.
We will follow these topics in this session:-
- What is a Kubernetes ReplicaSet?
- Why Use a ReplicaSet?
- How Does ReplicaSet Work?
- ReplicaSet vs. ReplicationController
- ReplicaSet vs. Deployment
- Anatomy of a ReplicaSet YAML File
- Creating a ReplicaSet in Kubernetes
- Verifying and Managing ReplicaSets
- Scaling ReplicaSets
- Best Practices.
What is a Kubernetes ReplicaSet?
A ReplicaSet is a Kubernetes controller that is responsible for maintaining a stable set of replica Pods running at any given time. In simpler terms, it ensures that a specified number of identical Pod replicas are running in the cluster at all times.
If a Pod fails, is deleted, or crashes, the ReplicaSet automatically creates a new one to replace it. This guarantees availability and reliability for your application.
Official Definition:-
A ReplicaSet ensures that a specified number of pod replicas are running at any given time.In Kubernetes, Pods are ephemeral—they can come and go due to restarts, crashes, or node failures. The ReplicaSet maintains the desired state by continuously monitoring and correcting the actual number of Pods running.
Why Use a ReplicaSet?
Here are several key reasons why ReplicaSets are used: –
1. High Availability
By running multiple replicas of a Pod, you ensure that your application is available even if one or more Pods crash or become unavailable.
2. Fault Tolerance
If a Pod fails due to some issue, the ReplicaSet will automatically spawn a new one to take its place.
3. Scalability
ReplicaSets allow you to scale your application up or down easily by adjusting the number of replicas.
4. Load Distribution
With multiple Pods running across nodes, traffic can be load-balanced among them using a Kubernetes Service.
How Does ReplicaSet Work?
A ReplicaSet works by matching labels defined in its specification with labels on existing Pods. It continuously monitors the number of Pods that match and takes action accordingly.
Key Concepts: –
- Selector: The label selector defined in the ReplicaSet specification.
- Template: Defines how new Pods should be created (metadata, containers, etc.).
- Replicas: Desired number of Pods to run.
If the number of matching Pods is less than the specified replicas, the ReplicaSet creates new Pods. If more Pods exist than required, it deletes extra Pods.
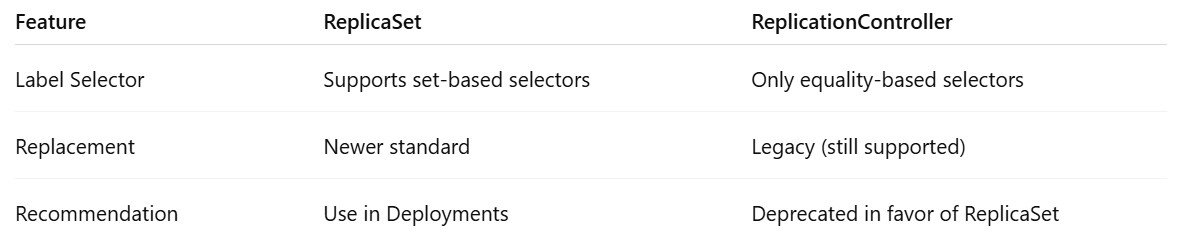
ReplicaSet vs. ReplicationController
Before ReplicaSets, Kubernetes used a controller called ReplicationController for the same purpose. ReplicaSet is the next-generation replacement with improved capabilities.
ReplicaSet vs. Deployment
While a ReplicaSet ensures a number of Pods are always running, it does not handle rolling updates, rollbacks, or versioning. That’s where Deployments come in.
A Deployment is a higher-level abstraction that manages ReplicaSets and supports:
- Rolling updates
- Rollbacks
- Revision history
- Declarative updates
You typically don’t use ReplicaSet directly in production but manage it through Deployments.
Anatomy of a ReplicaSet YAML File
Let’s look at the structure of a simple ReplicaSet manifest file.
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: my-replicaset
labels:
app: demo-app
spec:
replicas: 3
selector:
matchLabels:
app: demo-app
template:
metadata:
labels:
app: demo-app
spec:
containers:
- name: demo-container
image: nginx:1.21
ports:
- containerPort: 80
Breakdown:
- apiVersion:
apps/v1is the standard for ReplicaSets. - kind: Declares this object is a
ReplicaSet. - metadata: Metadata for the ReplicaSet, like name and labels.
- spec.replicas: Desired number of Pods (here, 3).
- selector.matchLabels: The ReplicaSet will manage all Pods with this label.
- template: Template for the Pods to be created.
Create ReplicaSet in Kubernetes
To create a ReplicaSet, follow these steps:-
Step 1: Save the YAML File
Create a file named replicaset.yaml and paste the below configuration.
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: my-replicaset
labels:
app: demo-app
spec:
replicas: 3
selector:
matchLabels:
app: demo-app
template:
metadata:
labels:
app: demo-app
spec:
containers:
- name: demo-container
image: nginx:1.21
ports:
- containerPort: 80
Step 2: Create ReplicaSet in Kubernetes.
Use kubectl to apply the file: –
kubectl apply -f replicaset.yaml
Step 3: Verify the ReplicaSet in kubernetes
kubectl get rs
This will show something like below: –
NAME DESIRED CURRENT READY AGE
my-replicaset 3 3 3 10s
Step 4: Check the Pods
kubectl get pods -l app=demo-app
This filters the Pods using the label used in the ReplicaSet selector.
Verifying and Managing ReplicaSets in kubernetes
Describe ReplicaSet
To get detailed information: –
kubectl describe rs my-replicaset
This shows info about events, labels, selector, template, and managed Pods.
Delete a Pod
To test fault tolerance, delete one of the Pods:
kubectl delete pod <pod-name>
Within seconds, a new Pod will be created to maintain the desired replica count.
Scaling ReplicaSets in kubernetes
You can scale the number of replicas dynamically using kubectl:
Scale Up:
kubectl scale rs my-replicaset --replicas=5
Scale Down: –
kubectl scale rs my-replicaset --replicas=2
Confirm Scaling: –
kubectl get rs
And check Pods:
kubectl get pods
Common ReplicaSet Use Cases
- Stateless Microservices: Running replicas of stateless containers like web servers.
- Batch Jobs with Retry: Managing retries by ensuring failed Pods are recreated.
- Load Testing Environments: Creating multiple instances of an app under test.
- Proof-of-Concept Applications: Simple, stable setups for demos or prototypes.
Best Practices
- Use Deployments Instead of Raw ReplicaSets: For rolling updates and rollback capabilities.
- Always Use Labels and Selectors Wisely: Misconfigured selectors can lead to unwanted behavior.
- Avoid Manual Pod Creation: Let the ReplicaSet manage Pod lifecycle.
- Monitor Replica Health: Use tools like Prometheus, Grafana, or Kubernetes dashboard.
- Name Uniqueness: Ensure your Pods have unique labels if running multiple ReplicaSets.
ReplicaSet Troubleshooting
If Pods aren’t created as expected: –
Check Logs: –
kubectl logs <pod-name>
Describe the ReplicaSet: –
kubectl describe rs my-replicaset
Watch events: –
kubectl get events
Common issues during creating replicaset in kubernetes: –
- Incorrect image name
- Misconfigured selectors
- Missing resources or limits
- Node scheduling problems
Conclusion
The Kubernetes ReplicaSet is a fundamental building block in ensuring the availability, scalability, and resilience of containerized applications. It may not be as commonly used directly as Deployments today, but understanding how ReplicaSets work under the hood gives you a solid grasp of Kubernetes architecture and helps in advanced scenarios like custom controllers or troubleshooting.
To summarize: –
- A ReplicaSet ensures a specified number of Pods are running.
- It replaces failed Pods and maintains high availability.
- You can create, scale, and manage ReplicaSets using YAML and
kubectl. - For most production scenarios, use Deployments, which manage ReplicaSets for you.
You can also check this below link related to Kubernetes: –
What is Kubernetes namespace and how to create it?
What is Kubernetes pod and why we use Kubernetes pod?
How to Upload Image in Kubernetes?
Understanding Kubernetes Storage: A Beginner’s Guide
Kubernetes Networking Concepts, Architecture, and Best Practices